Tpetra: Norm2 (dot) is substantially slower than direct calls to TPL BLAS
Created by: jjellio
When strong scaling an app, we noticed the norm2 (among other things) is 'blowing' up. In this case, the customer has a challenging problem that they want to strong scale, while using 2 processes per node and 16 threads per process (On Haswell nodes). The problem, is that this results in relatively small work per process for the dense linear algebra, and KokkosKernels::BLAS does not impose a reasonable minimum chunk size for its operations.
Considering that vendor BLAS is Intel's MKL, it isn't surprising that is performs very well. This leaves a reasonable question: Why doesn't Tpetra prefer vendor BLAS?
To support my argument, I modified Belos' MultiVectorTrait::norm2 to call TPL BLAS ddot rather than Tpetra::norm2 (which if you follow the rabbit hole, eventually calls KokkosKernels::BLAS:dot).
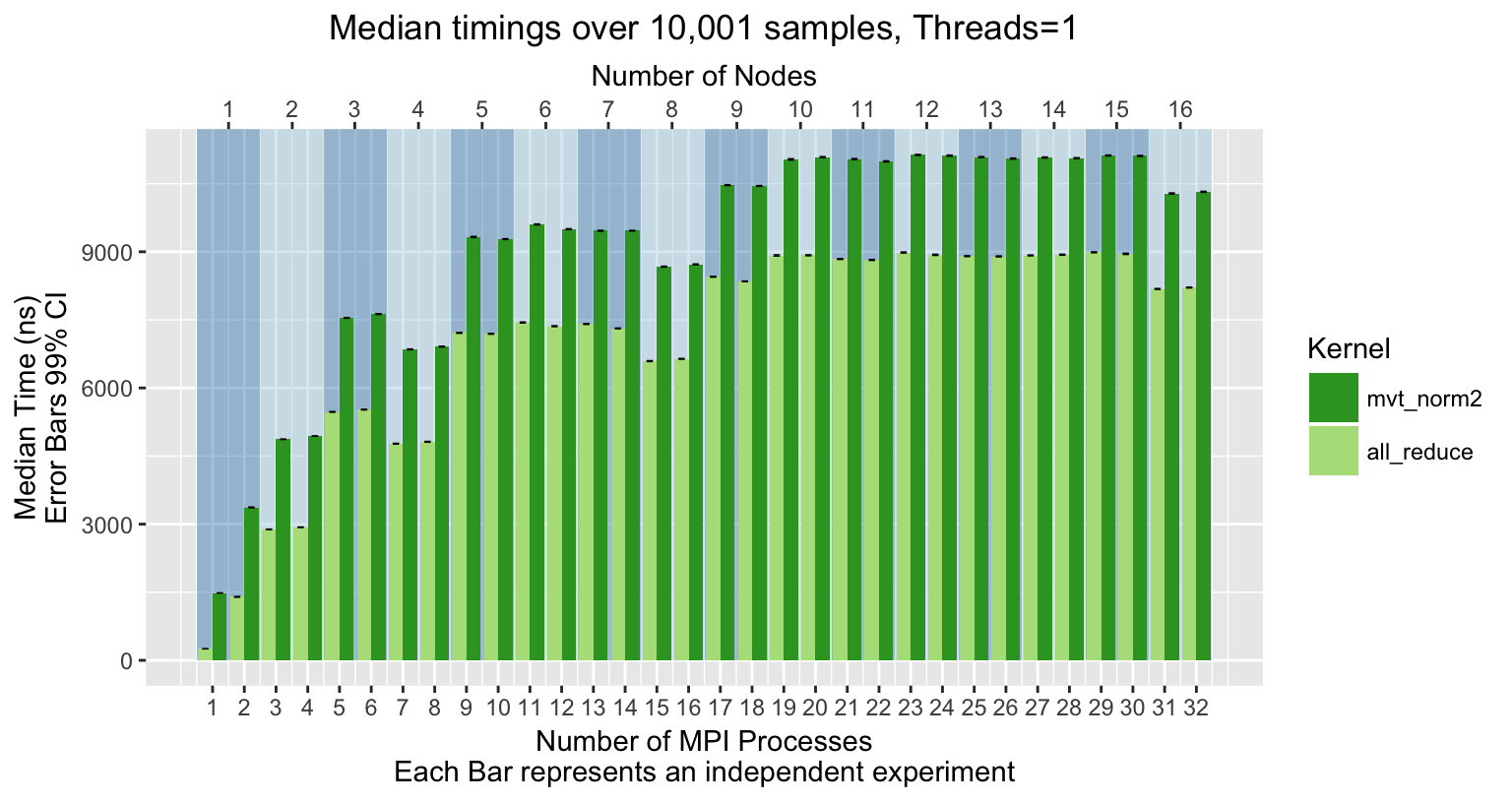
I wrote a simple test code that calls MVT::Norm2 a few thousand times in a loop. I profiled this code linked against my modified MVT and the vanilla Trilinos one. (I.e., TPL ddot vs Kokkos dot). For the experiment, I fixed the data per MPI process to 1000 elements (i.e., a very small work size). I then weak scale this perfectly, incrementally filling nodes with 2 processes.
I also profiled the cost of Teuchos::reduceAll, with a single scalar. I ran this with OMP_NUM_THREADS=1 and 16.
Regular MVT::norm2 and All Reduce (1 thread)
Regular MVT::norm2 and All Reduce (16 thread)

All Reduce unaffected by threads

Using TPL dot with 1 or 16 threads

TPL ddot vs Kokkos


While I profiled norm2, the issue is really the underlying call to ddot. In this case, MKL is doing a much better job of throttling back it's thread count. Still, calling the threaded BLAS is an overall loss, and in this case calling a purely serial MKL would have been better.
One option to mitigate the lack of thread scaling we see, is to enforce compute ensure that BLAS operations are called with a meaningful chunk size. A simpler solution, that would reduce the Trilinos code base, would be to call TPL BLAS for Serial/Thread/and OpenMP execution spaces.
This contradicts the recommendation in #2850 (closed)
@trilinos/tpetra @trilinos/kokkos-kernels